Meet SmolLM3
The compact 3B parameter language model that punches above its weight. SmolLM3 delivers exceptional multilingual reasoning, long-context understanding, and tool-calling capabilities while remaining efficient enough for edge deployment.
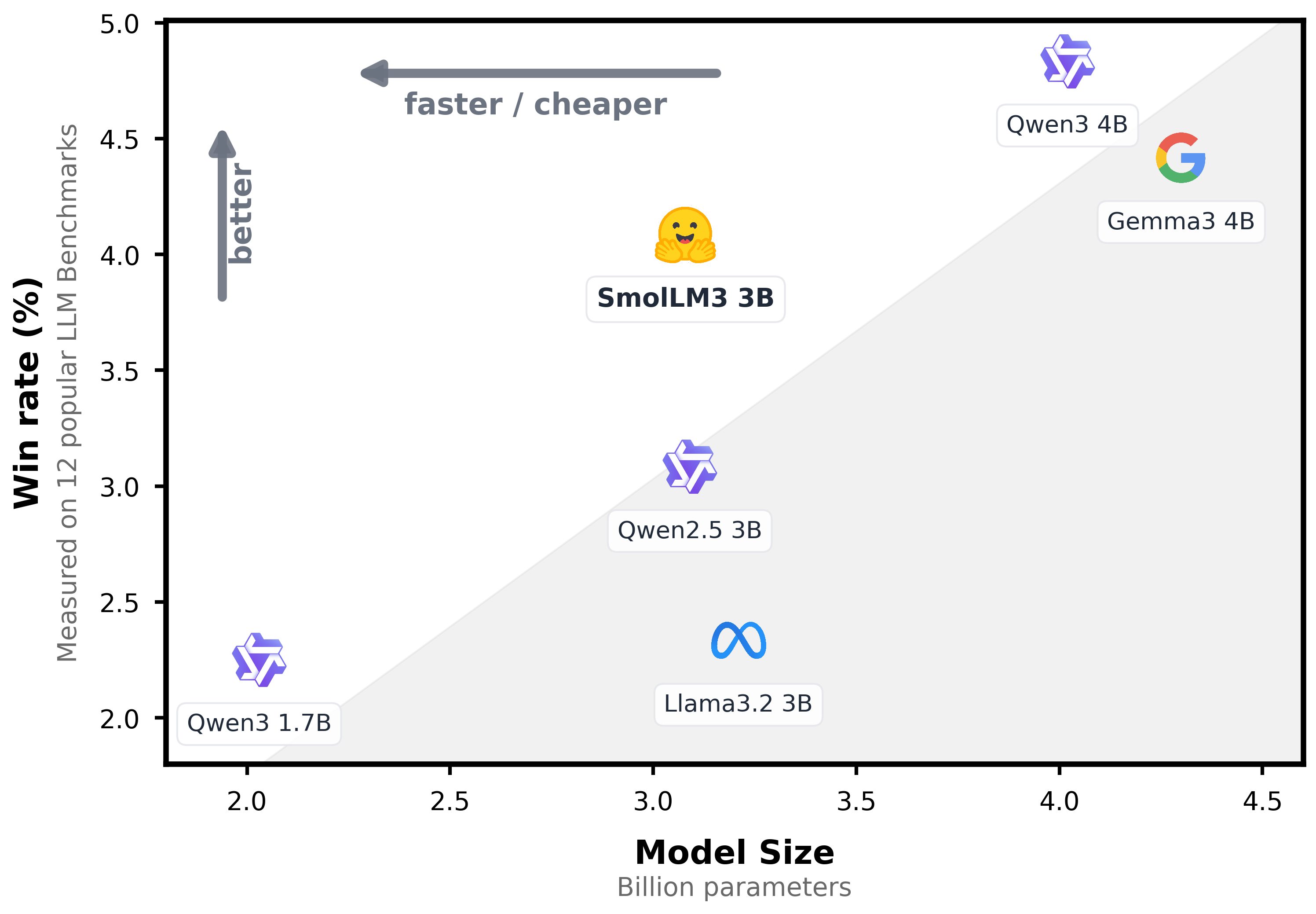
Image credit: https://huggingface.co/HuggingFaceTB/SmolLM3-3B
Small Size, Big Capabilities
SmolLM3 represents a new paradigm in language model efficiency. By carefully optimizing architecture and training approaches, we've created a model that delivers enterprise-grade performance while remaining compact enough for widespread deployment.
Compact Yet Powerful
3B parameters delivering performance comparable to much larger models
Despite its compact size, SmolLM3 achieves remarkable performance through efficient architecture and high-quality training data
Long Context Understanding
Process up to 128,000 tokens for comprehensive document analysis
Handle entire books, research papers, and long conversations while maintaining coherent understanding
Multilingual Reasoning
Native support for 6 languages with consistent quality across all
English, French, Spanish, German, Italian, and Portuguese with seamless cross-lingual capabilities
Dual-Mode Intelligence
Switch between fast responses and deep reasoning as needed
Choose between quick answers for simple tasks or detailed reasoning for complex problems
Engineering Excellence
Efficient Architecture
SmolLM3 employs a carefully optimized transformer architecture with 3 billion parameters. The model uses grouped-query attention and depth-over-width prioritization to maximize performance per parameter. This design philosophy enables sophisticated reasoning capabilities while maintaining computational efficiency.
High-Quality Training Data
Trained on 11 trillion tokens from curated datasets including FineWeb-Edu, DCLM, and The Stack. The training corpus emphasizes educational content, code, and multilingual text to ensure broad knowledge coverage while maintaining factual accuracy and coherent reasoning capabilities.
Advanced Context Handling
The model processes contexts up to 128,000 tokens through optimized attention mechanisms that minimize computational complexity. This enables analysis of entire documents, long conversations, and complex multi-step reasoning tasks while maintaining coherent understanding throughout.
Model Specifications
Benchmark Performance
SmolLM3 achieves competitive performance across diverse evaluation tasks, demonstrating strong reasoning, knowledge retention, and multilingual capabilities that rival much larger models.
HellaSwag
75.2%Common sense reasoning
ARC-Challenge
62.8%Science reasoning
MMLU
55.7%World knowledge
GSM8K
45.2%Mathematical reasoning
HumanEval
29.4%Code generation
MGSM
38.9%Multilingual math
These benchmarks demonstrate SmolLM3's ability to compete with models 2-3x its size. The model excels particularly in multilingual tasks, long-context understanding, and reasoning scenarios while maintaining efficiency that enables deployment in resource-constrained environments.
Real-World Applications
SmolLM3's unique combination of compact size and powerful capabilities opens up new possibilities for AI deployment across various domains and environments.
Edge Deployment
Run sophisticated AI on mobile devices, edge servers, and constrained environments
Document Analysis
Process lengthy documents with full context understanding and detailed insights
Multilingual Support
Build applications that work consistently across multiple languages
Tool Integration
Create intelligent agents that can use external tools and APIs effectively
Try SmolLM3 Interactive Demo
Experience SmolLM3's capabilities firsthand with our interactive demo. Test the model's reasoning, multilingual support, and long-context understanding in real-time.
Powered by Hugging Face Spaces - Experience SmolLM3's coding and reasoning capabilities
Get Started with SmolLM3
Begin your journey with SmolLM3 using our comprehensive resources and community support.
Documentation
Complete guides, API references, and tutorials to help you integrate SmolLM3 into your applications.
Hugging Face Hub
Download pre-trained models, access tokenizers, and explore community fine-tuned versions.
Community
Join our community of developers and researchers building with SmolLM3 across various applications.
Frequently Asked Questions
Get answers to common questions about SmolLM3 and how to use it in your projects.
What is SmolLM3 and how is it different from other language models?
▼
What is SmolLM3 and how is it different from other language models?
▼SmolLM3 is a compact, multilingual language model designed for efficiency without compromising performance. Unlike larger models, SmolLM3 is optimized for edge computing, mobile applications, and resource-constrained environments while maintaining high-quality language understanding and generation capabilities.
What languages does SmolLM3 support?
▼
What languages does SmolLM3 support?
▼SmolLM3 supports over 30 languages including English, Spanish, French, German, Chinese, Japanese, Arabic, and many more. The model has been trained on diverse multilingual datasets to ensure robust performance across different languages and cultural contexts.
What are the system requirements to run SmolLM3?
▼
What are the system requirements to run SmolLM3?
▼SmolLM3 can run on devices with as little as 4GB RAM and basic CPU configurations. For optimal performance, we recommend 8GB RAM and a modern processor. GPU acceleration is optional but recommended for faster inference and training tasks.
Can I fine-tune SmolLM3 for my specific use case?
▼
Can I fine-tune SmolLM3 for my specific use case?
▼Yes! SmolLM3 is designed to be easily fine-tuned for domain-specific applications. You can customize the model for tasks like chatbots, content generation, code completion, or any other language-related task using your own datasets.
Is SmolLM3 free to use for commercial applications?
▼
Is SmolLM3 free to use for commercial applications?
▼SmolLM3 is released under an open-source license that allows both personal and commercial use. Please refer to the license documentation for specific terms and conditions regarding redistribution and modification.
How do I integrate SmolLM3 into my existing application?
▼
How do I integrate SmolLM3 into my existing application?
▼SmolLM3 can be integrated using popular frameworks like Hugging Face Transformers, PyTorch, or TensorFlow. We provide comprehensive APIs, SDKs, and examples for Python, JavaScript, and other programming languages. Check our documentation for step-by-step integration guides.
What kind of performance can I expect from SmolLM3?
▼
What kind of performance can I expect from SmolLM3?
▼SmolLM3 delivers impressive performance despite its compact size. It achieves competitive scores on standard benchmarks while maintaining fast inference speeds. Typical response times range from 50-200ms depending on hardware and query complexity.
Where can I get support if I encounter issues?
▼
Where can I get support if I encounter issues?
▼Our community provides excellent support through GitHub issues, Discord channels, and discussion forums. We also offer comprehensive documentation, tutorials, and examples. For enterprise users, dedicated support packages are available.